目前,政务、金融、医疗等多行业均存在数据合规流通的需求,隐私计算如何在各行各业中实现应用落地,实现技术价值到应用价值的转化?本期我们邀请到RealAI数据科学家杨秋语、RealAI解决方案专家杨金威从业务场景的角度来聊一聊隐私保护计算应用那些事。
核心观点梳理:
1. 典型的数据需求场景与数据使用方式
第一类:同业之间,联合同业数据提升数据总量,进行联合反欺诈、运营效率提升等,比如银行与银行之间;
第二类:跨行业,例如银行在做反欺诈的过程中,需要其他的行业提供数据支持,打通行业间数据,拓宽数据维度,进行营销、反欺诈、运营等建模;
第三类:个人到机构,指机构需要采集个人终端各类信息进行相关的业务应用,像APP可能会采集个人的一些行为数据,但是基于隐私保护,部分字段无法采集,这就是个人到机构的数据应用;
第四类:机构整合数据源,一些机构或参与方通过把各方数据源的数据进行整合,参与到数据交易市场里面去交易。
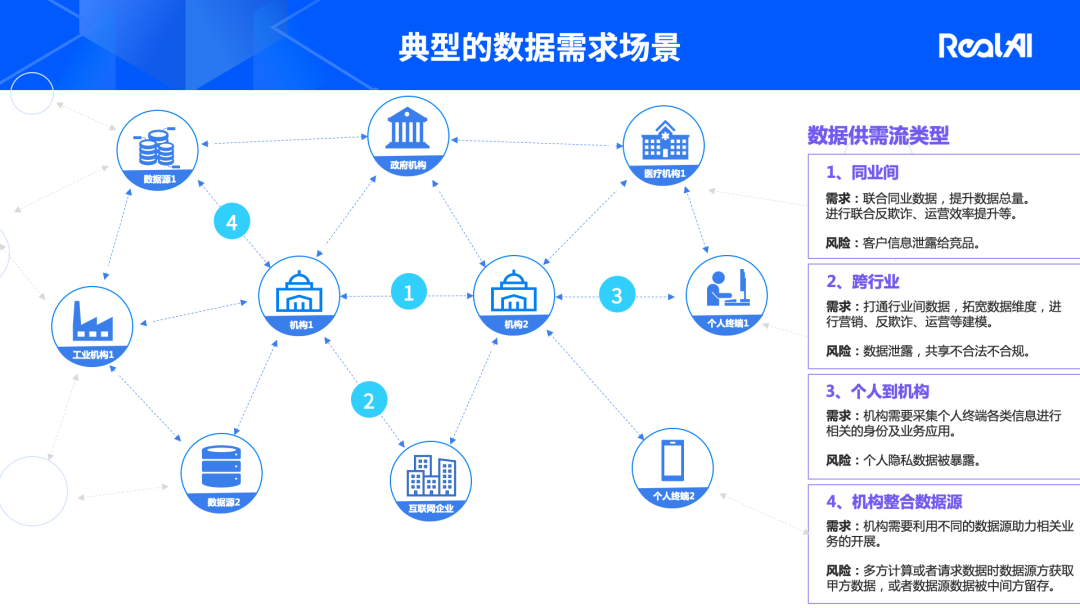
在这四类典型场景中,实际使用过程中涉及的数据使用方式主要涉及两方面:
数据统计:通过统计各方数据获取汇总统计结果,具体包括数值运算和向量运算,使用面相对会少一些;
数据分析:利用各方数据训练模型,挖掘信息价值,具体包括分类、回归、聚类、网络模型等,应用场景相对较多。
2. 传统的数据共享方式
从数据科学这个角度上看,不管是数据统计还是数据分析都面临一个数据匹配/共享的问题,传统的数据匹配/共享的方式包括三种:
.png)
(1)明文数据对接:数据不敏感的情况下,直接明文数据匹配,但数据处于直接暴露的状态;
(2)哈希数据对接:在有一定隐私保护的需求下,采用哈希、MD5、SHA256等加密算法,将敏感信息隐去后再进行数据匹配,这种方式会相对安全一些,但数据匹配的过程中,数据的接收方可以知道发送方取走了哪部分交集,仍存在不安全的因素;
(3)第三方可信平台对接:近几年兴起的一种方式,通过一个公信的第三方协调数据资源,比如大数据交易平台,将各种数据对接到一块联合发挥作用,但第三方平台需要考虑安全和效率上的平衡,并且需要经过安全评估以及审核的流程。
3. 数据隐私保护的技术路径
(1)单一场景/专用技术形式:上期分享中提到的不经意传输;
(2)通用技术形式:在数据分散或者联邦的场景下,采用一些通用技术来解决统计和建模的问题,主要包含两条技术路径:
秘密分享:需要借助第三方,基本原理是将数据拆分成小块,让每一方只计算其中的一部分,最终希望得到结果的那一方再将小块的结果汇总到一起得到最终结果;
同态加密:无需借助第三方,基本原理是对数据进行加密,使用密文进行计算,最终解密方再将结果解成明文,中间的过程交互全部以密文的方式进行。
4. 数据隐私保护实现—联邦学习
联邦学习用于解决数据孤岛问题,在分散的数据上去训练一个汇总的模型,在保证隐私的训练过程交互中,让数据产生相应的价值。从基本定义来看,联邦学习主要可分成两类:
横向联邦学习:每个参与方都有对应标签和相应特征,类似于分布式计算,几方合力去计算出一个模型,去预测、跑批,最后产生相应的结果,对每一方的数据要求比较苛刻;
纵向联邦学习:产出模型的那一方有标签,但特征可能很少或者说没有,通过利用其他方的数据来作为特征,训练出一个整体的模型,来让外部数据产生它相应的价值。
.png)
5. 联邦学习在金融场景的应用
(1)智能营销:银行传统的营销模式,是基于行内存量的数据对客户做一个画像,这个过程中能参考的数据量是有限的。比如手机银行能参考的只是设备类信息,是用户在申请这项产品时自行登记的信息,这部分信息的是有限的。所以,行方可能会采购一些外部的三方数据源,但大多时候它们提供的数据还是基于一些能接触到的数据源,然后进行二次处理,最终给到银行的是评分、标签,需要银行在这些二次处理过的数据基础上再去做模型,这对银行原有模型的增益是有限的。
.png)
如果采用联邦学习的模式,银行来说就能够把可以参考的特征维度扩展到非常大。之前可参考的建模用的基础字段非常少,而且可信度也会降低,用了联邦学习之后,可以用到非常底层的字段,拿这些基础的底层字段衍生出来的特征,对于模型的贡献度是非常大的,再对应到银行的营销场景中,它的转化率能有非常大的提升。
(2)智能风控:银行的另一个常见场景就是风控场景,这个场景对于数据源的需求量更大。在传统风控场景下,比如评分卡场景,银行积累的通常是存量客户标签,比如说违约了那就是坏标签,能参考到的特征数是有限的,基于这样的数据建出来的模型存在上限,很难突破,这种情况下,银行会选择接入一些外部数据源来支撑它建模。
但外部数据源所能提供的数据质量和数据量存在同质化,同样在数据质量上也很难有突破。所以如果采用联邦学习这种模式的话,外部数据源接进来对于用户的特征维度会有一个很大的扩展,数据质量也会有很大的提升,这种情况下,在风控层面建立的模型,识别率和响应率会有很好的表现。
6. 理想的隐私保护计算产品
.png)
开箱即用:
从应用层面来看,使用者会希望提供到一个拿来即用的工具,在实现隐私保护计算功能的同时,不会对传统建模和统计的方式产生影响;另外,平台支持提前接入外部的一些第三方数据源,用户通过平台可直接使用外部数据源,而用户已经合作的数据源也能够很容易的实现接入,用户想使用哪家的数据都可以在平台上直接选择;同时对于常用的智能营销、智能风控、智能催收还有智能定价这类模型,平台能够将这些常用的建模流程做成模版,用户想用的时候可以直接加载进来,后续只需再做一些迭代性的工作即可。
零学习成本:
从技术层面来看,使用者会希望学习门槛大幅降低,统计层面能够将常用的统计算子集成到平台,建模层面将常用的AI算法都集成到平台,直接调用,另外对于一些自研的算法,能够快速的通过平台把它转变成联邦的版本或者多方安全计算的版本,支持快速上手;
兼顾安全与性能:
联邦学习是一个密码学、AI和传统计算机科学的交叉学科的产物。所以,联邦学习平台首先需要保证安全性,从密码学的角度去验证它的安全性是绝对可靠的,才能够在传输过程中真正保证数据不泄露。另一方面,相比传统建模,联邦学习涉及传输和交互的过程,不光需要本地的机器,还需要和远程的服务器进行通讯,中间的过程十分耗时,通常来讲联邦学习的模型,它的运行效率都是比本地建模要慢很多的,因此性能优化也是一个重中之重。