导读
本文为中国科学院张钹院士关于人工智能发展趋势的分析判断,主要回顾人工智能发展的历史,以及系统阐释第三代人工智能的特点、发展现状及未来趋势。
作者简介:
张钹,清华大学计算机系教授,中科院院士。1958年毕业于清华大学自动控制系,同年留校任教至今。1980年2月‐1982年2月美国伊利诺斯大学访问学者。2011年汉堡大学授予自然科学荣誉博士。曾任校学位委员会副主任,现任微软亚洲研究院技术顾问,“探臻科技评论”顾问委员会委员。
在过去30多年中,他提出问题求解的商空间理论,在商空间数学模型的基础上,提出了多粒度空间之间相互转换、综合与推理的方法。提出问题分层求解的计算复杂性分析以及降低复杂性的方法。在人工神经网络上,他提出基于规划和基于点集覆盖的学习算法。
我是清华大学人工智能研究院——张钹,我今天想讲的是迈向第三代人工智能。人工智能60年的历史中,一共经历了两代的发展。第一代人工智能,有时候称它作符号主义。他们提出了基于知识和经验的推理模型,用这个模型来模拟人类的理性智能行为,像推理、规划、决策等等。根据这个原理,需要在机器里面建立知识库和推理机制,利用这两者对人类的推理和思考行为进行模拟。

图1 张钹院士在2020世界人工智能大会上演讲
下面举一个例子,1971年左右,美国斯坦福大学根据这个原理建造的一个专家系统,叫做MYCIN系统,主要用来诊断血液传染病和开抗菌素处方。它把传染病专家的知识放在计算机里头,并且把医生诊断的过程(如何从症状推到疾病,然后进行处方)作为推理机制,也放在计算机里头。这样,计算机就可以帮助内科医生进行辅助诊断。因为内科医生一般不是传染病专家,因此利用这样的计算机辅助治疗系统可以帮助内科医生做出更好的、更准确的诊断和处方。
利用这种原理做的人工智能系统,一个最有代表性的成果就是国际象棋程序IBM的深蓝。这个国际象棋程序,在1997年5月打败了世界冠军卡斯帕罗夫。

图2 IBM深蓝与世界冠军卡斯帕罗夫下棋
我们看一下,计算机的深蓝程序为什么可以打败人类的象棋大师呢?主要是三个要素,第一个要素是知识和经验,也就是说他利用了人类大师下过的70万盘棋局,还有全部的5-6只的残局。分析这些棋局,总结成为下棋的规则,并放进计算机。然后又通过大师和机器之间的对弈,调试评价函数中的参数,把大师的经验也放在程序里头。

图3 IBM深蓝成功的原因
第二个靠的是算法,使用阿尔法-贝塔剪枝算法,这个算法的速度很快。第三个是算力,IBM当时用的RS/6000SP2机器,每秒能够分析2亿步,平均每秒钟能够往前预测8-12步。一个有经验的象棋大师,一般只能往前看3-5步,机器的速度远超过人类,因此可以超过人类的下棋水平。

图4 第一代人工智能的优势
第一代人工智能的优势,在于它能够模仿人类的推理、思考的过程,因此是可解释的,跟人类的思考问题过程很一致。利用这个办法进行机器学习,就能够举一反三,所以这是第一代人工智能的优势。

图5 第一代人工智能的局限
但是第一代人工智能也存在着非常严重的缺陷,例如:这些知识都来自于专家。大家都知道专家的知识十分稀缺,也非常昂贵。而且通常要通过人工编程把它输进计算机,非常费时费力。同时有很多知识是很难表达的,比如说那些不确定的知识、常识等等,因此第一代人工智能的应用范围非常有限。
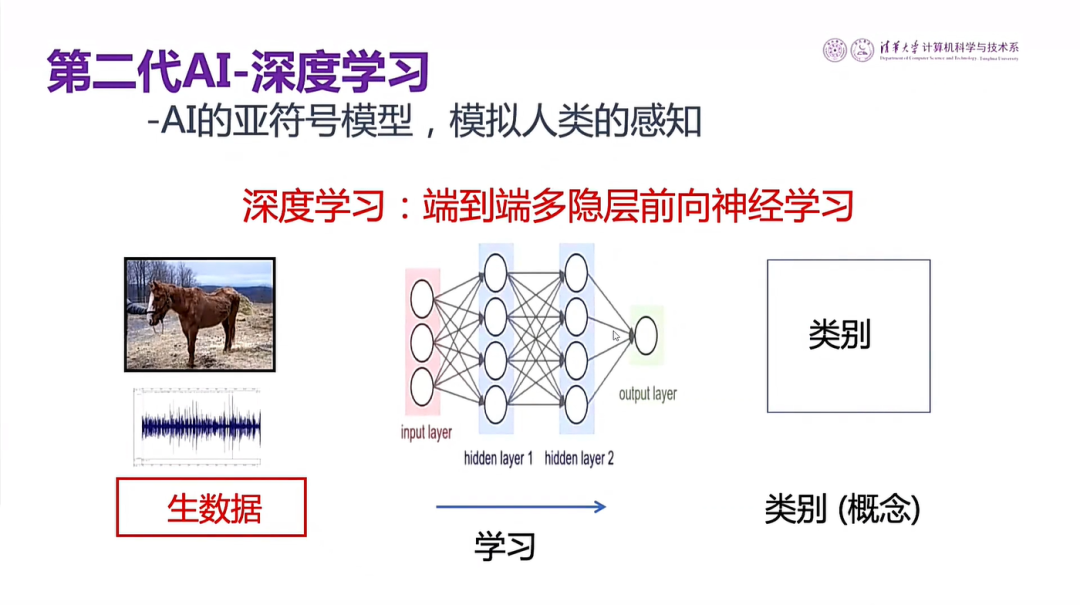
图6 第二代人工智能模拟人类感知的过程报
第二代人工智能,就是大家非常熟悉的深度学习。所谓深度学习,就是通过深度神经网络的模型模拟人类的感知,如:视觉、听觉、触觉等行为。我们用图像识别作为例子,看看计算机是怎样模拟人类的感知的。比如我们要想让计算机识别不同的动物,怎么办呢?因为我们没法把什么叫做马,什么叫做牛?告诉计算机。我们只好采用人类学习的办法,即先收集了大量有关动物的图片,并把图片分成两类。一类作为训练图片,去训练计算机识别马和其他动物,这叫做分类学习。把图像输进去训练计算机,让他能够正确地分出马牛等动物的种类,叫做学习与训练阶段。
学习用的是多层次神经网络,你把大量的图片输进去作为训练。训练以后,究竟机器是不是学好了,我们再把另一部分图片(没有学习过的图片)让它识别。如果90%说对了,就说他识别率是90%,误识率为10%。用这种办法来进行图像和语音识别,在给定的图像(语音)库下,可以做到达到或超过人类的识别水平。

图7 深度学习对人工智能发展的影响
我们再举一个例子来看深度学习的优点。首先,第一个优点是它不需要领域知识,技术门槛比较低。换句话讲,我们只要把原始图片、原始语音输进去就可以了,不要告诉计算机怎么去识别图片或者语音,即不需要领域知识,所以任何人都可以使用这种工具。
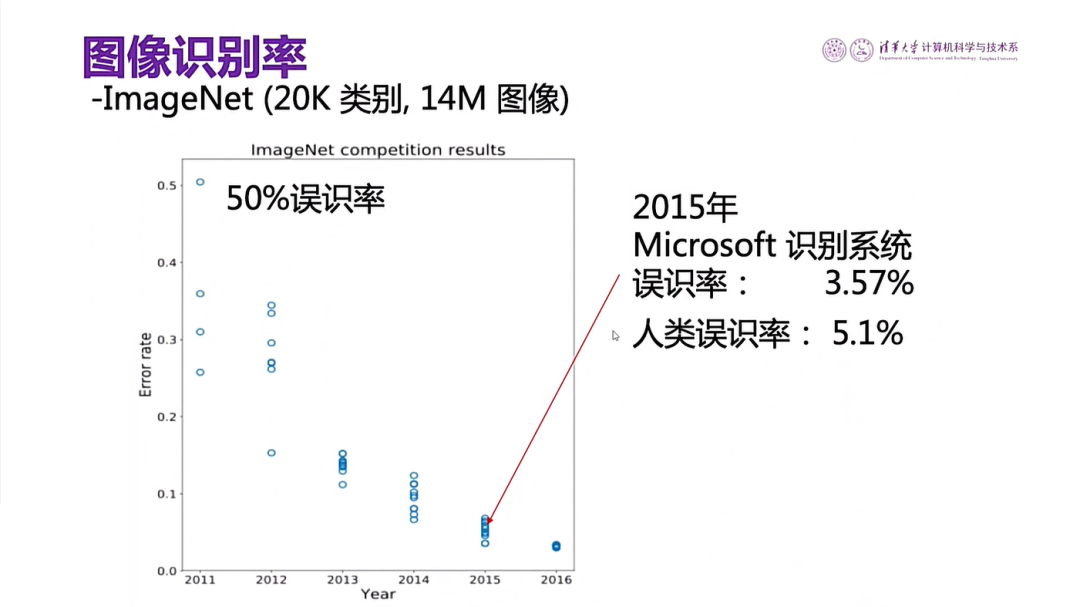
图8 深度学习的图像识别率
第二个,由于神经网络规模很大,所以可以处理大数据。利用这个办法可以达到人类的图像识别的水平,甚至超过它。这里举一个例子,一个叫做ImageNet的图像库有2万种类别,一共有1400万张图,这是一个标准图像库。2011年计算机识别ImageNet图像库里头的图,误识率高达50%,也就是说一半认错了。可是4年以后,2015年微软用深度学习的办法来识别,误识率降到3.57%,比人类的误识率5.1%还要低。因此深度学习受到广大用户的关注。
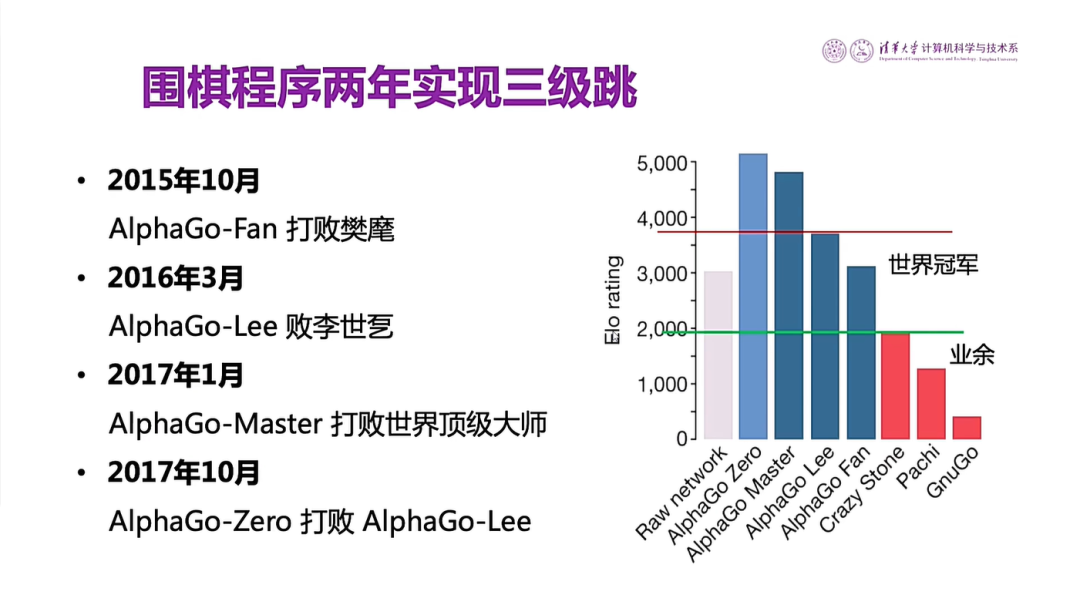
图9 深度学习的应用对围棋程序的影响
关于深度学习的应用,一个最典型的例子是围棋程序。在2015年10月之前,我们用第一代知识驱动的方法做出来的围棋程序,最高达到业余5段的水平。到了2015年10月份,围棋程序打败了欧洲的冠军,到2016年3月份打败了世界冠军。到2017年10月份,AlphaGo元打败了AlphaGo,说明在两年时间里,由于利用了深度学习,使得围棋程序的水平实现了三级跳,从业余跳到专业水平,又从专业水平到世界冠军,又从世界冠军到超过世界冠军。

图10 AlphaGo成功的秘诀
AlphaGo两年里头实现了三级跳,它的成功来自于何处?主要来自于三个方面,一个是大数据,一个是算法,一个是算力。可以看到AlphaGo的确利用了大数据,他一共学习了3000万盘已有的棋局,自己跟自己又下了3000万盘,一共6000万盘棋局,这个数据量是很大的。他用的算法是蒙特卡罗树搜索、强化学习、深度学习等等。利用巨大的计算能力,一共有1202个CPU和280个GPU,也就是说他的成功是靠三个要素。但是,第二代人工智能有很大的局限性,比如:不可解释性、不安全性、易受攻击、不易推广、需要大量的样本等等。

图11 第二代人工智能的局限
这里只举一个简单的例子,这是我们博士生做出来的例子。左边这张图片是阿尔卑斯雪山,计算机的图像识别系统用94.39%的信度,认定它是阿尔卑斯山。但是,我们只要加一点点噪声,变成右边这张图。右边这张图跟左边这张图,人的眼睛看起来几乎是完全一样的,只是多了一点点噪声,但是计算机却以99.99%的把握,识别它是一只狗。我们可以看到计算机的模式识别系统跟人类的视觉差别非常大。尽管它的识别率很高,但是与人类的视觉感知完全不同,非常不安全、非常不可靠,而且不可解释。它为什么把雪山解释成一只狗呢?我们没法理解。

图12 计算机把阿尔卑斯山误识为狗
从第一代和第二代人工智能的成就来看,人工智能只能算刚刚拉开了序幕。我们刚才说过,第一代和第二代人工智能都有很大的缺陷,它的应用范围非常有限,更精彩的大戏正要上演,这也是我今天讲的主题。全世界应该团结起来,共同来发展人工智能,让人工智能造福人类。那么这场大戏是什么样子,又该怎么演呢?下面将根据我们团队的工作做一个简单的说明。
第三代人工智能必须解决第一代和第二代人工智能中间存在的缺陷。这个缺陷有以下几方面,它们是不可解释,鲁棒性很差,还有不安全、不可信、不可靠、不可扩展等。所以,我们必须要建立一个可解释和鲁棒的人工智能理论,必须发展安全、可信、可靠和可扩展的人工智能技术,只有这样才能实现技术上的突破。有了技术上的突破,才能推动人工智能的创新应用。那么我们用的办法是什么?就是把第一代知识驱动的方法和第二代数据驱动的方法结合起来。换句话讲,我们要综合地利用四个要素,即知识、数据、算法和算力。而第一代人工智能只用了其中的三个要素,第二代人工智能也只用了其中的三个要素。

图13 第三代人工智能的要素
第三代人工智能要充分利用这四个要素,知识、数据、算法和算力。下面简单地讲一下我们是怎么解决同时应用4个要素的问题?

图14 计算机识别马的过程
环境感知,我们刚才说过人工智能的图像识别系统虽然识别率很高,但是由于它识别的办法跟人类非常不一样,所以非常不可靠,非常不安全,非常容易受到攻击。我们看一下机器是怎么识别马呢?它只是把每匹马的局部特征给分析出来,然后跟其他动物作比较,根据局部特征进行区别,这就是我们常常讲的黑箱学习方法。也就是说它只能学习那些局部的底层特征,学习不了高层的语义特征,因此只能分辨马和牛,但并不认识马和牛。
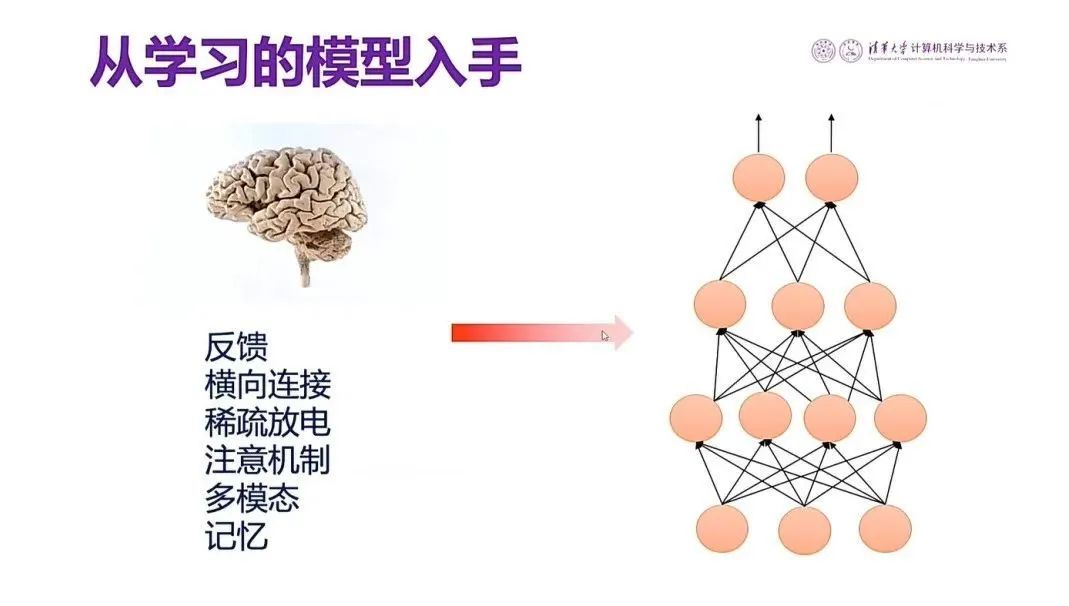
图15 人脑的学习模型
那么我们怎么来做这个工作?首先要借鉴人脑的工作机制,我们知道人脑的视觉神经也是多层的神经网络,但跟我们现在用的人工神经网络相比的话,现在用的人工神经网络则太简单了,只有底下一层跟上层的联系,这叫做前向连接。
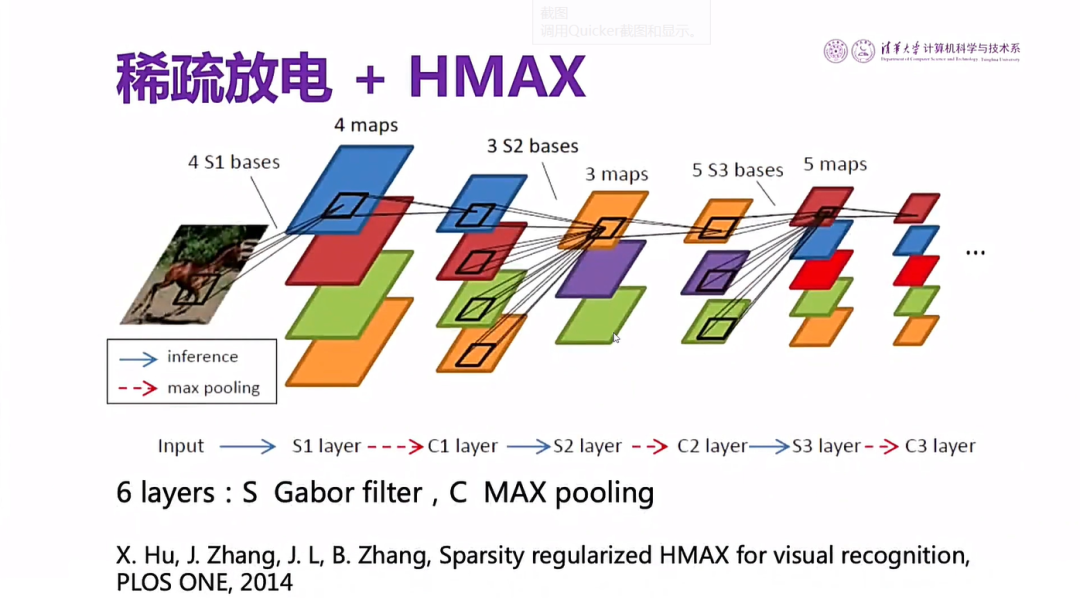
图16 人脑稀疏放电过程
人脑里头的视觉神经网络比这个要复杂得多,其中有反馈连接,横向连接,稀疏放电,注意机制,多模态和记忆等等。如果我们能把人类视神经网络的这些特点加到现有的人工神经网络去,就可以改善现在图像识别或者语音识别的性能,这是我们今天需要做的一项工作。
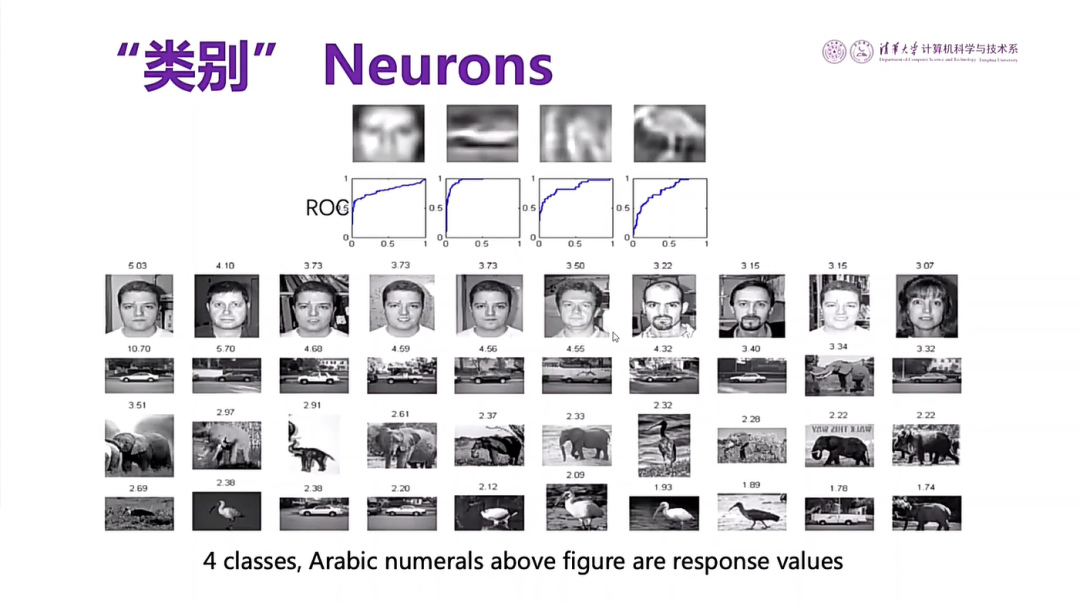
图17 神经网络检测物体轮廓的过程
下面是我们团队的一项工作,即把稀疏放电原理加到神经网络里头去。仅借助这一点,就可以看到在神经网络最顶部的神经元可以检测到人脸的轮廓、小汽车的轮廓、大象的轮廓或者鸟的轮廓。说明能够把语义的特征检测出来。说明把人类神经网络的一些特点加进现有的人工神经网络有可能改善现有图像识别,语音识别等所存在的弱点,当然这还只是初步的工作。
目前图像识别还有一个很大的问题,就是很难把物体,比如马和背景分开。也就是说我们很难检测到马在什么地方,也不知道什么是马。那么怎么解决这个问题呢,我们还是要向大脑学习。

图18 计算机识别马和背景的过程
人类为什么一看就知道马在哪里,因为我们认识马。那么“马”的知识是从哪里学来的呢?实际上,是从我们不断的观察中学来的。我们用一个自编码的神经网络,也可以学习到这个知识,也就是说通过无监督的学习,可以学到“马”的知识。
图19 神经网络学习知识的过程
认识了马以后,你就很容易在图像中找到马,这样就很容易识别“马”了。我们做了一些初步工作,取得一些初步的成果(如图20和图21所示)。
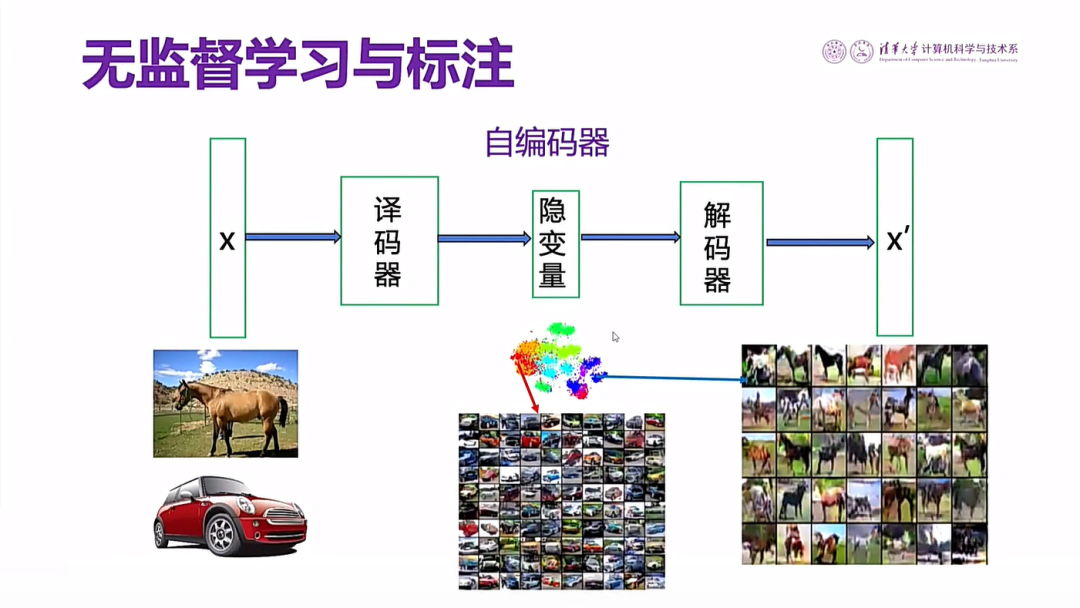
图20 无监督学习的过程
第二个关于安全性的问题,我们刚才说过,人工智能模式识别系统或其他机器识别系统都非常不安全,非常容易受到攻击。我们也可以从数据上和模型上进行改进。
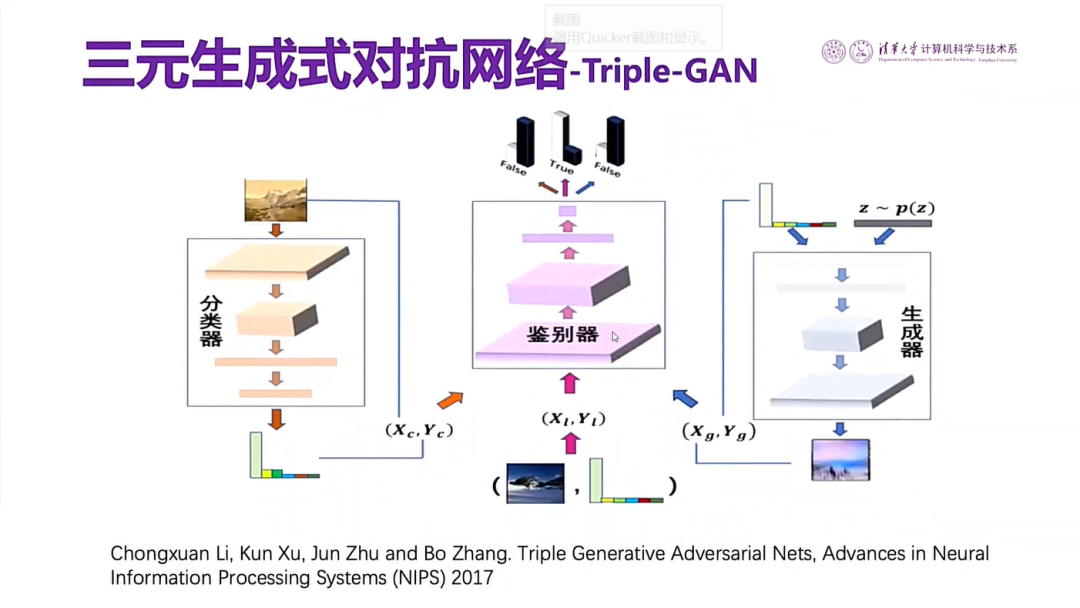
图21 三元生成式对抗网络
这里只举一个例子,即人脸识别。大家经常用人脸识别登录手机,我们看左边这个人跟用户不是同一个人,所以他进不去。系统识别出来他不是用户,但只要加上一个人造的眼镜,他就可以混进去了。
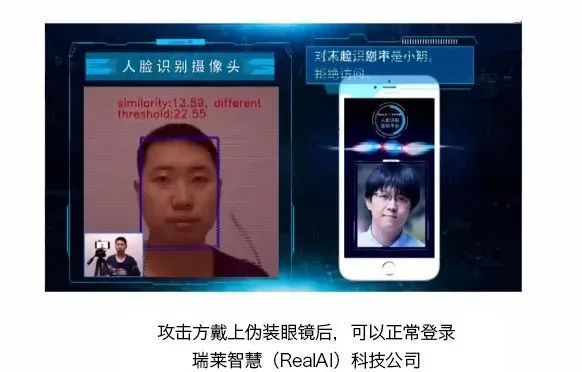
图22 人脸识别过程
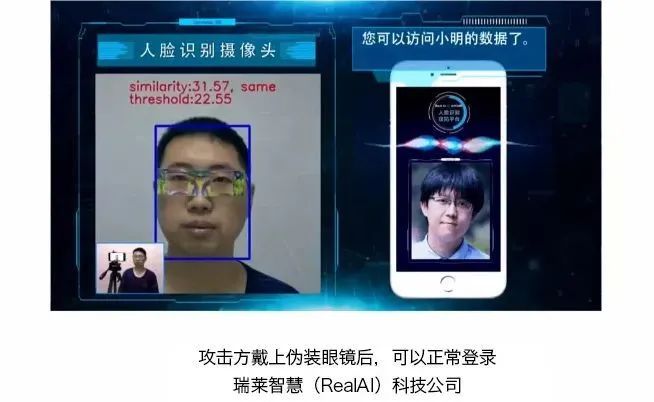
图23 人造伪装眼睛欺骗人脸识别
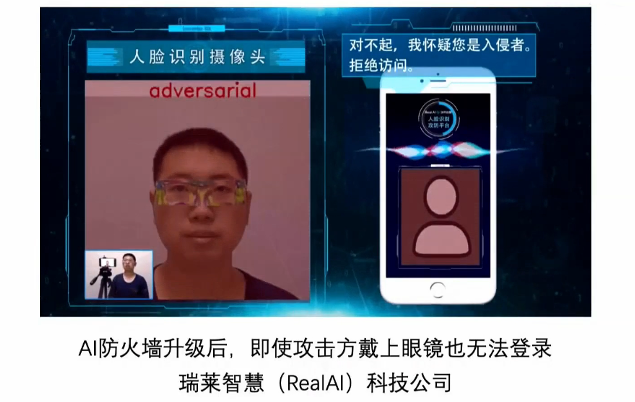
图24 AI防火墙反入侵
加上AI防火墙之后,加强了防护能力。现在即使戴上伪装眼镜,也进不去了,说明我们可以用各种各样的办法来提高它的安全性。

图25 提高AI安全性的防御方法
我们已经有了一个开源的“珠算”平台,把目前我们已有的研究成果集成在这个平台上,在算法的可解释性、安全性上都有一定的提高。
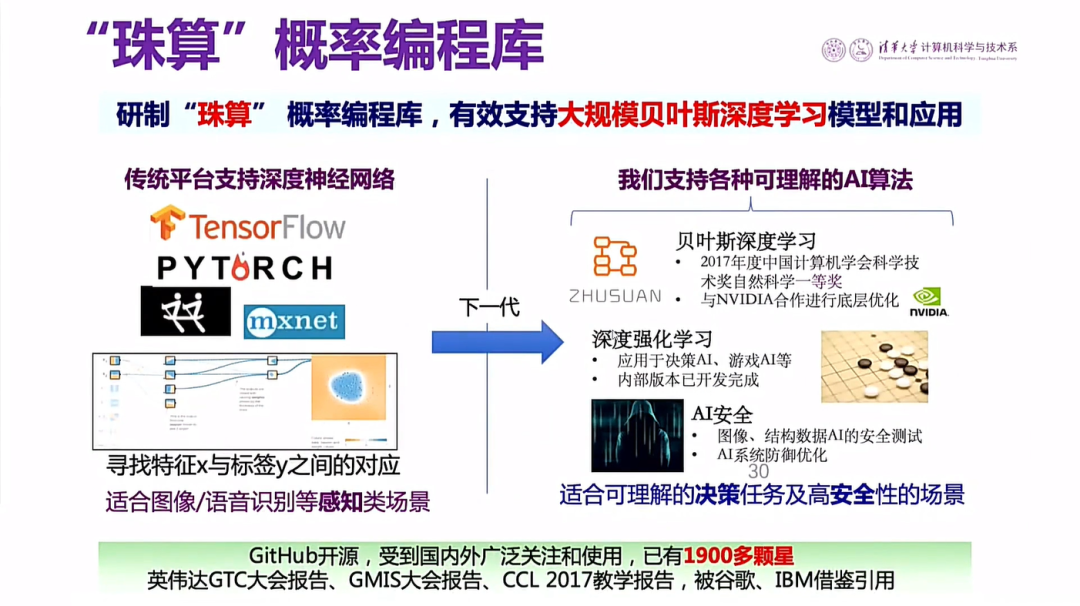
图26 “珠算”概率编程库
关于推理和决策,人工智能在棋类上打败了人类,包括围棋和象棋,这些都是完全信息博弈,对计算机来讲是比较简单的。

图27 推理与决策
牌类是不完全信息博弈,计算机打牌就困难得多。2017年人工智能才在6人无限注德州扑克牌上战胜了人类。

图28 复杂环境下的自主决策
牌类属于概率意义下确定的问题,而我们平常的决策环境是完全不一样的,是完全不确定的,甚至是在对抗环境下做决策。目前研究对抗环境下的决策,往往用电子游戏比赛做实验平台。

图29 对抗性场景中的自主决策
电子游戏的环境是变化的,不确定性的,有防卫和进攻等等。通常采用强化学习的办法,目前只能在少数特定的游戏上可以打败人类。
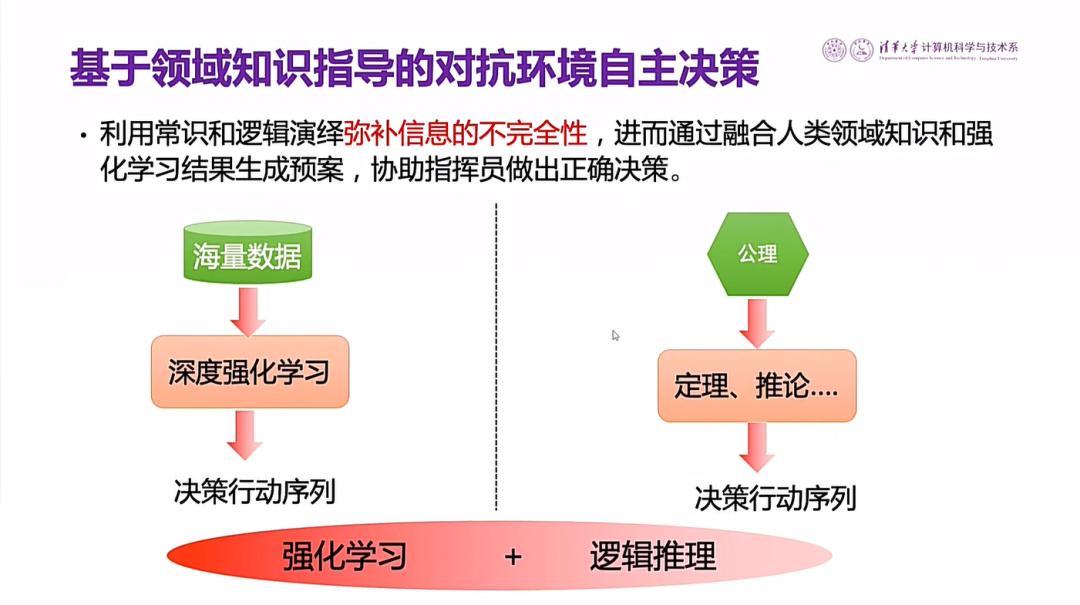
图30 基于领域知识指导的对抗环境自主决策
图31是我们采用的对抗环境下自主决策的方案,主要依靠知识和强化学习。在ViZDoom国际比赛中,取得第二名的好成绩,跟第一名的CMU只差两分。后来我们团队还参加了多次国际比赛,赢得多项冠军。
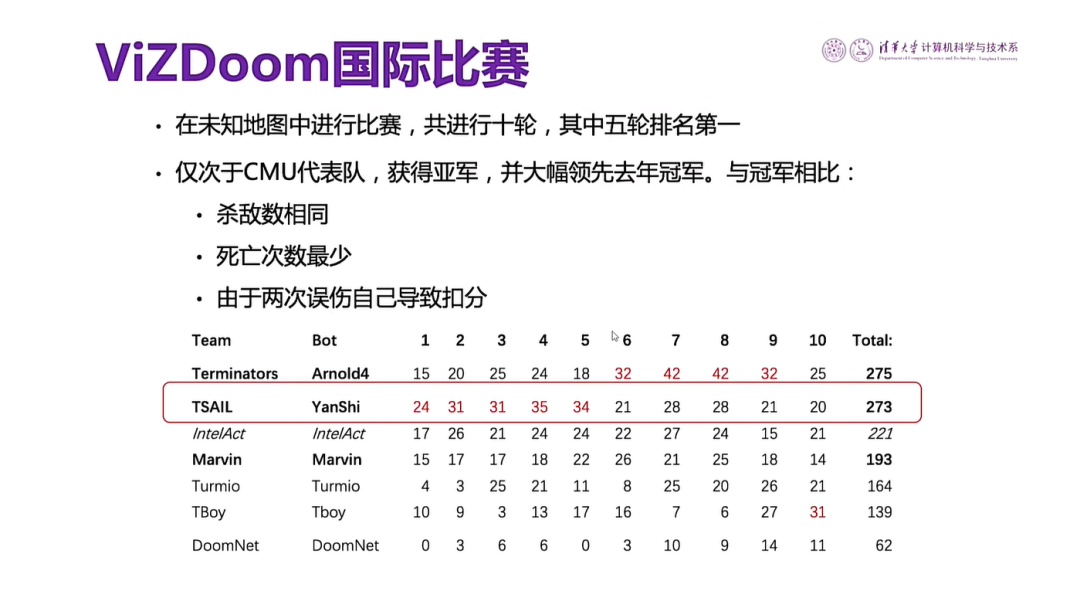
图31 ViZDoom国际比赛成绩

图32 多项科技获奖
还有一个问题是,如何适应环境变化,即解决随机应变的问题。自动驾驶车我们从1991年就开始做了,自动驾驶车的问题在哪里?我们现在采用的办法是,把物体识别出来,建立模型,在此基础上做驾驶规划。这些步骤现在都已经做到实时了。是否能够实用?如果路况比较复杂,这种方案就不够用了,为什么?它难以应对突发事件。为了应对突发事件,需要驾驶的知识与经验,需要在与环境的不断交互过程中学习这些经验,这就是所谓的强化学习。
图33 自动驾驶环境感知过程
要让自动驾驶车真正用到复杂的环境中,需要经过学习训练这个步骤,学习应对突发的情况。我们团队开发了一个平台,叫“天授”,是一个强化学习的开源平台。
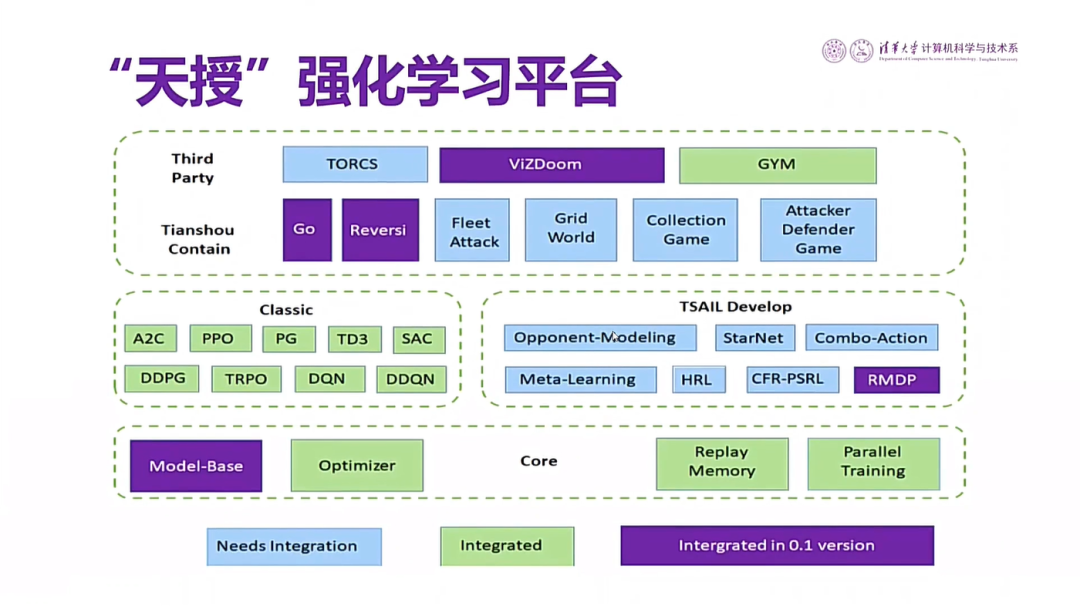
图34 “天授”强化学习平台
最后强调一下,人工智能刚刚拉开序幕。第一代和第二代人工智能都存在着很大的局限,它只能够解决完全信息和结
